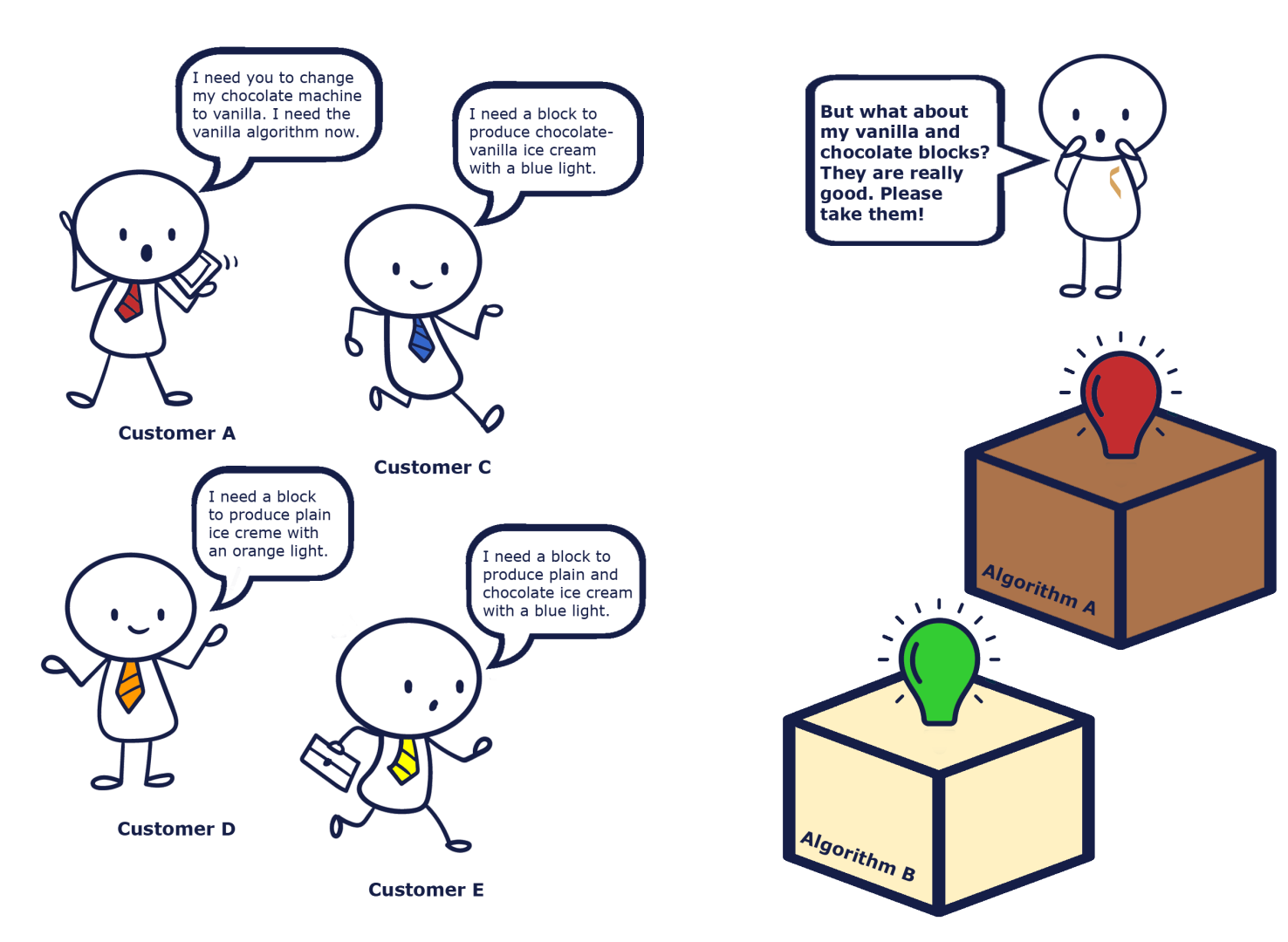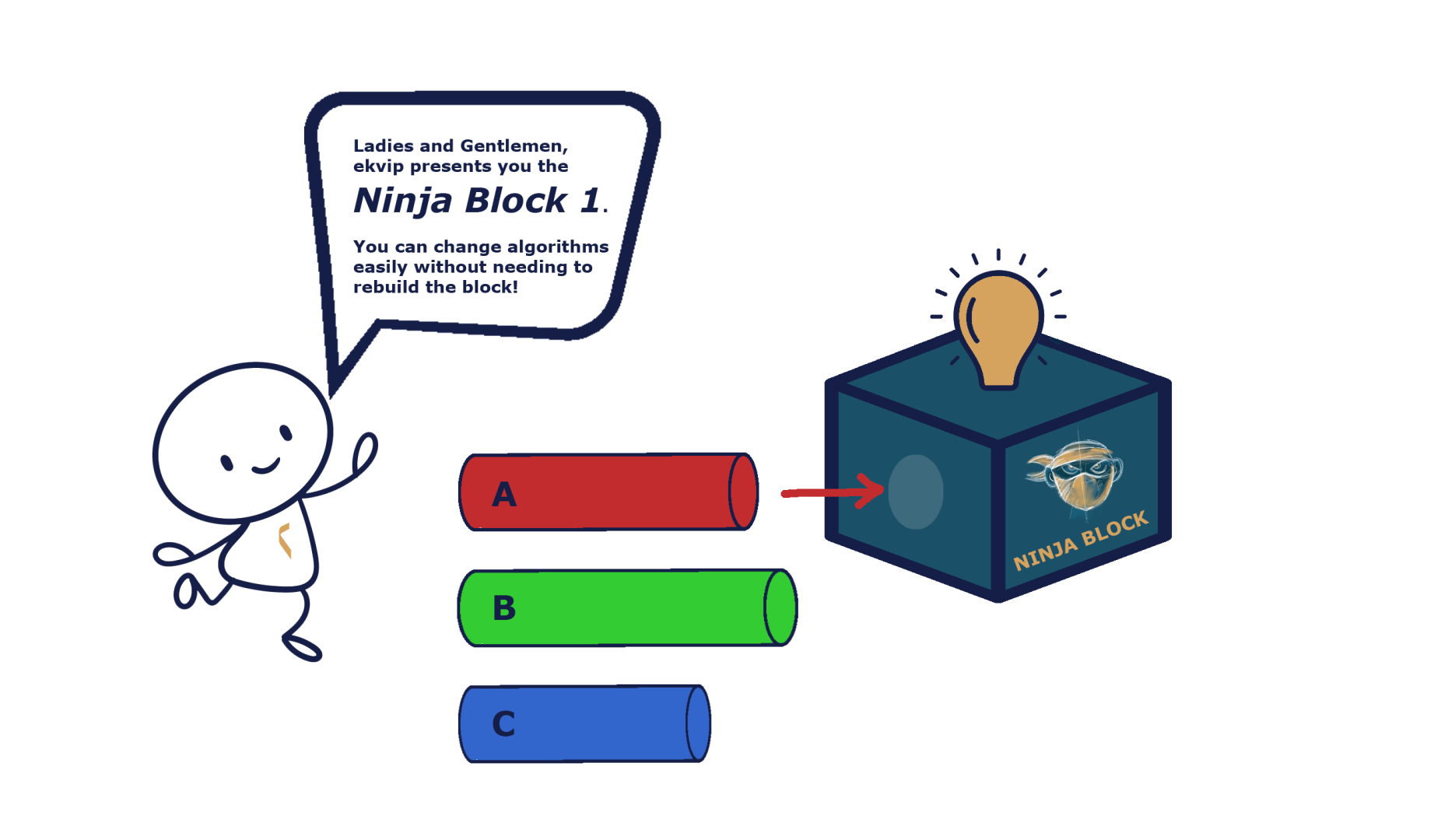
The definition of strategy patterns is as follows: „Strategy patterns define a family of algorithms, encapsulate each one, and make them interchangeable.“ The strategy allows the algorithm to vary independently of the clients who use it. Okay, now we understand strategy patterns. Very simple.
Joking aside, let’s look at the definition and analyze it. So we need a set of algorithms, i.e. pieces of code that perform certain tasks. They must belong to a family, which means that they must have something in common. They also need to be encapsulated and interchangeable, which means we can use one instead of the other. After reading the definition, the following questions may arise:
Why do I need to encapsulate algorithms and make them interchangeable? Can’t I just change the algorithm when necessary?
How do I do it?